library(tidyverse)Web Scraping with rvest
Learning Objectives
- Basics of Web Scraping
- Chapter 24 of RDS
- Overview of rvest.
- SelectorGadget.
- Web Scraping
Data on the Web
There are at least 4 ways people download data on the web:
- Click to download a csv/xls/txt file.
- Use a package that interacts with an API.
- Use an API directly.
- Scrape directly from the HTML file.
This lesson, we talk about how to do 4.
Note: You shouldn’t download thousands of HTML files from a website to parse — the admins might block you if you send too many requests.
Note: Web scraping can be illegal in some circumstances, particularly if you intend to make money off of it or if you are collecting personal information (especially in Europe). I don’t give legal advice, so see Chapter 24 of RDS for some general recommendations, and talk to a lawyer if you are not sure.
Let’s load the tidyverse:
HTML / CSS
We have to know a little bit about HTML and CSS in order to understand how to extract certain elements from a website.
HTML stands for “HyperText Markup Language”
<html> <head> <title>My First Web Page</title> </head> <body> <h1>Welcome!</h1> <p>This is a <b>simple</b> paragraph.</p> <a href="https://en.wikipedia.org/">Wikipedia</a> </body> </html>HTML consists of elements which start with a tag inside
<>(like<head>and<body>), optional attributes that format the element (likehref=url), contents (the text), and an end tag (like</head>and</body>). The above HTML text would be formatted like this:
Welcome!
This is a simple paragraph.
WikipediaImportant tags for web scraping:
<h1>–<h6>: Heading tags, with<h1>as the highest (most important).<p>: Paragraph of text.<a>: Creates hyperlinks to other pages or resources.<img>: Embeds an image.<div>: Generic container for layout and styling.<span>: Inline container for styling parts of text.<ul>: Unordered list (bulleted).<ol>: Ordered list (numbered).<li>: List item, used inside<ul>or<ol>.<table>: Defines a table structure.<tr>: Table row.<td>: Table data cell.<th>: Table header cell.<strong>: Strong importance (usually bold).<em>: Emphasized text (usually italic).
CSS stands from “Cascading Style Sheets”. It’s a formatting language that indicates how HTML files should look. Every website you have been on is formatted with CSS.
Here is some example CSS:
h3 { color: red; font-style: italic; } footer div.alert { display: none; }The part before the curly braces is called a selector. It corresponds to HTML tags. Specifically, for those two they would correspond to:
<h3>Some text</h3> <footer> <div class="alert">More text</div> </footer>The code inside the curly braces are properties. For example, the h3 properties tells us to make the h3 headers red and in italics. The second CSS chunk says that all
<div>tags of class"alert"in the<footer>should be hidden.CSS applies the same properties to the same selectors. So every time we use h3 will result in the h3 styling of red and italicized text.
CSS selectors define patterns for selecting HTML elements. This is useful for scraping because we can extract all text in an HTML that corresponds to some CSS selector.
You can get a long way just selecting all
pelements (standing for “paragraph”) since that is where a lot of text lives.The most common attributes used are
idandclass.- The selectors corresponding to
classbegin with a dot.. - The selectors corresponding to
idbegin with a hashtak#.
- The selectors corresponding to
The
.aselector selects for “Text 1” in the following<p class="a">Text 1</p>The
.aselector selects for “Text 2” in the following<div class="a">Text 2</div>The
#bselector selects for “Text 3” in the following<p id="b">Text 3</p>The
#bselector selects for “Text 4” in the following<div id="b">Text 4</div>More complicated selectors (from Richard Ressler):
- The
nameselector just uses thenamevalue of the element such ash3. All elements with the same name value will be selected. - The
idselector uses a#, e.g.,#my_id, to select a single element withid=my_id(all ids are unique within a page). - The
classselector uses a., e.g.,.my_class, whereclass=my_class. All elements with the same class value will be selected. - We can combine selectors with
.,, and/or\to select a single element or groups of similar elements.- A selector of
my_name.my_classcombines name and class to select all (only) elements with thename=my_nameandclass=my_class.
- A selector of
- The most important combinator is the white space,
, the descendant combination. As an example,p aselects all<a>elements that are a child of (nested beneath) a<p>element in the tree. - You can also find elements based on the values of attributes, e.g., find an element based on an attribute containing specific text.
- For a partial text search you would use
'[attribute_name*="my_text"]'. Note the combination of single quotes and double quotes so you have double quotes around the value.
- For a partial text search you would use
- The
rvest
We’ll use
rvestto extract elements from HTML files.library(rvest)The typical pipeline for
rvestis:- Load the html file into R using
read_html() - Choose the selectors based on SelectorGadget (see below) or by inspecting the selectors manually using developer tools (see below).
- Select those selectors using
html_elements().- Possibly select elements within those elements via
html_element() - E.g.
html_elements()selects the observational units andhtml_element()selects values of variables within that unit.
- Possibly select elements within those elements via
- Extract the text using
html_text2().- Or, extract tables using
html_table().
- Or, extract tables using
- Extreme cleaning using 412/612 tools.
- Load the html file into R using
We’ll do a real example after we cover SelectorGadget and the web developer tools. But for now, let’s create a small html file:
html <- minimal_html(' <p class="a">Text 1</p> <div class="a">Text 2</div> <p id="b">Text 3</p> <div id="b">Text 4</div> ')We can get all
ptag text viahtml_elements(html, "p") |> html_text2()[1] "Text 1" "Text 3"We can get all
divtag text viahtml_elements(html, "div") |> html_text2()[1] "Text 2" "Text 4"We can get all
class=atext viahtml_elements(html, ".a") |> html_text2()[1] "Text 1" "Text 2"We can get all
id=btext viahtml_elements(html, "#b") |> html_text2()[1] "Text 3" "Text 4"Once you use
html_elements(), it’s common to then usehtml_element()to extract even more information.html_k <- minimal_html(" <p><emph>A</emph>: <b>Ape</b> picks an <b>Apple</b> for <b>Aardvark</b> below.</p> <p><emph>L</emph>: <b>Lion</b> <b>Lifts</b> <b>Ladybug's</b> <b>Luggage</b></p> <p><emph>P</emph>: <b>Penguin</b> <b>Plays</b> with <b>Platypus</b> in the <b>Pool</b></p> ")html_k |> html_elements("p") |> html_element("emph") |> html_text2()[1] "A" "L" "P"If you want all of the
bs that are within ap, you can use.html_k |> html_elements("p b") |> html_text()[1] "Ape" "Apple" "Aardvark" "Lion" "Lifts" "Ladybug's" [7] "Luggage" "Penguin" "Plays" "Platypus" "Pool"Exercise: Try extracting
bwith bothhtml_element()andhtml_elements(). What’s the difference?Exercise (from R4DS): Get all of the text from the
lielement below:html <- minimal_html(" <ul> <li><b>C-3PO</b> is a <i>droid</i> that weighs <span class='weight'>167 kg</span></li> <li><b>R4-P17</b> is a <i>droid</i></li> <li><b>R2-D2</b> is a <i>droid</i> that weighs <span class='weight'>96 kg</span></li> <li><b>Yoda</b> weighs <span class='weight'>66 kg</span></li> </ul> ")Exercise (from R4DS): Extract the name of each droid. Start with the output of the second exercise.
Exercise (from R4DS): Use the class attribute of
weightto extract the weight of each droid. Do not usespan. Start with the output of the second exercise.
SelectorGadget
SelectorGadget is a tool for you to see what selector influences a particular element on a website.
To install SelectorGadget, drag this link to your bookmark bar on Chrome: SelectorGadget
Suppose we wanted to get the top 100 movies of all time from IMDB. The web page is very unstructured:
https://www.imdb.com/list/ls055592025/
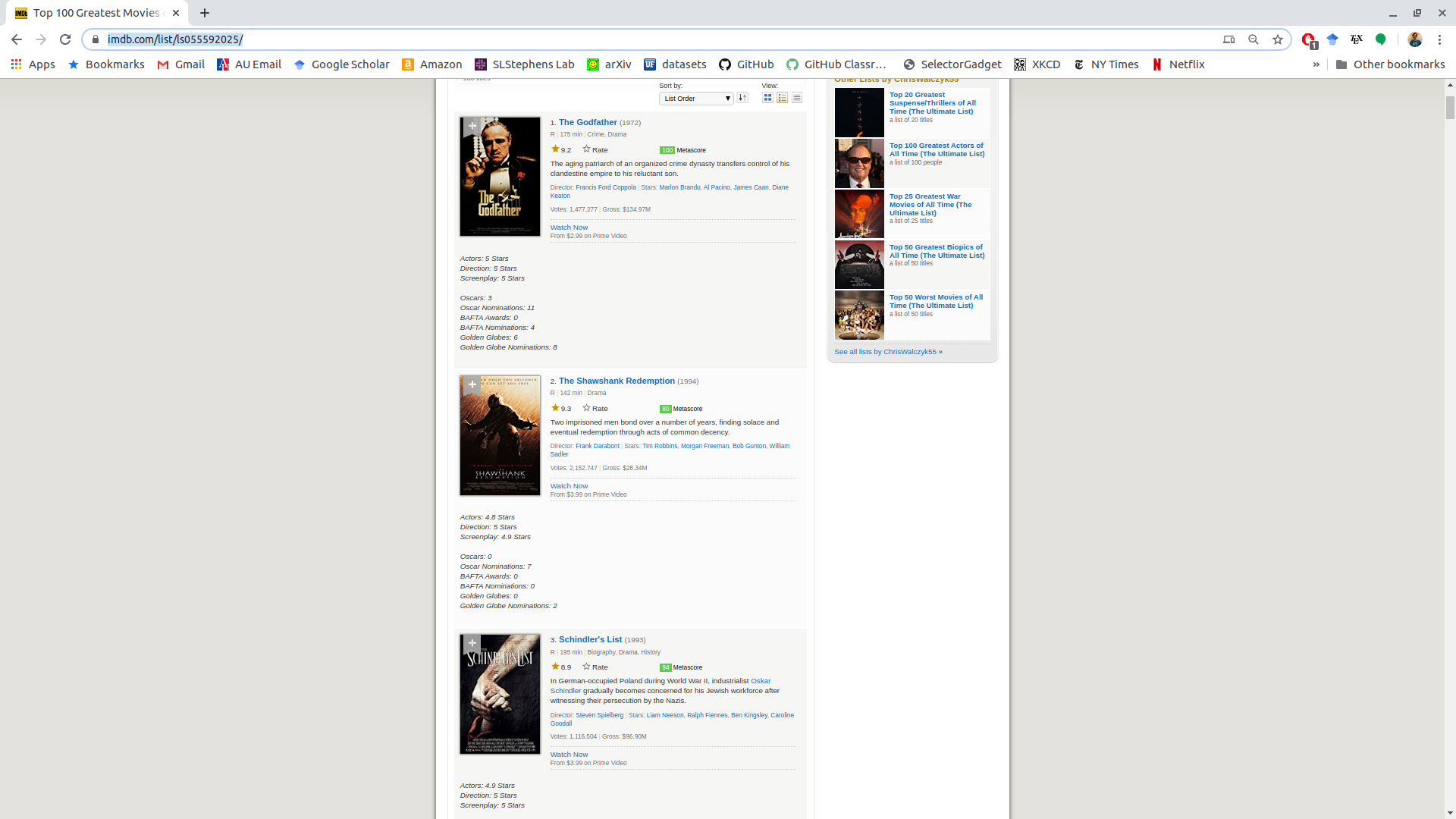
If the above link fails, try: https://data-science-master.github.io/lectures/08_web_scraping/imdb_100.html```
If we click on the ranking of the Godfather, the “1” turns green (indicating what we have selected).
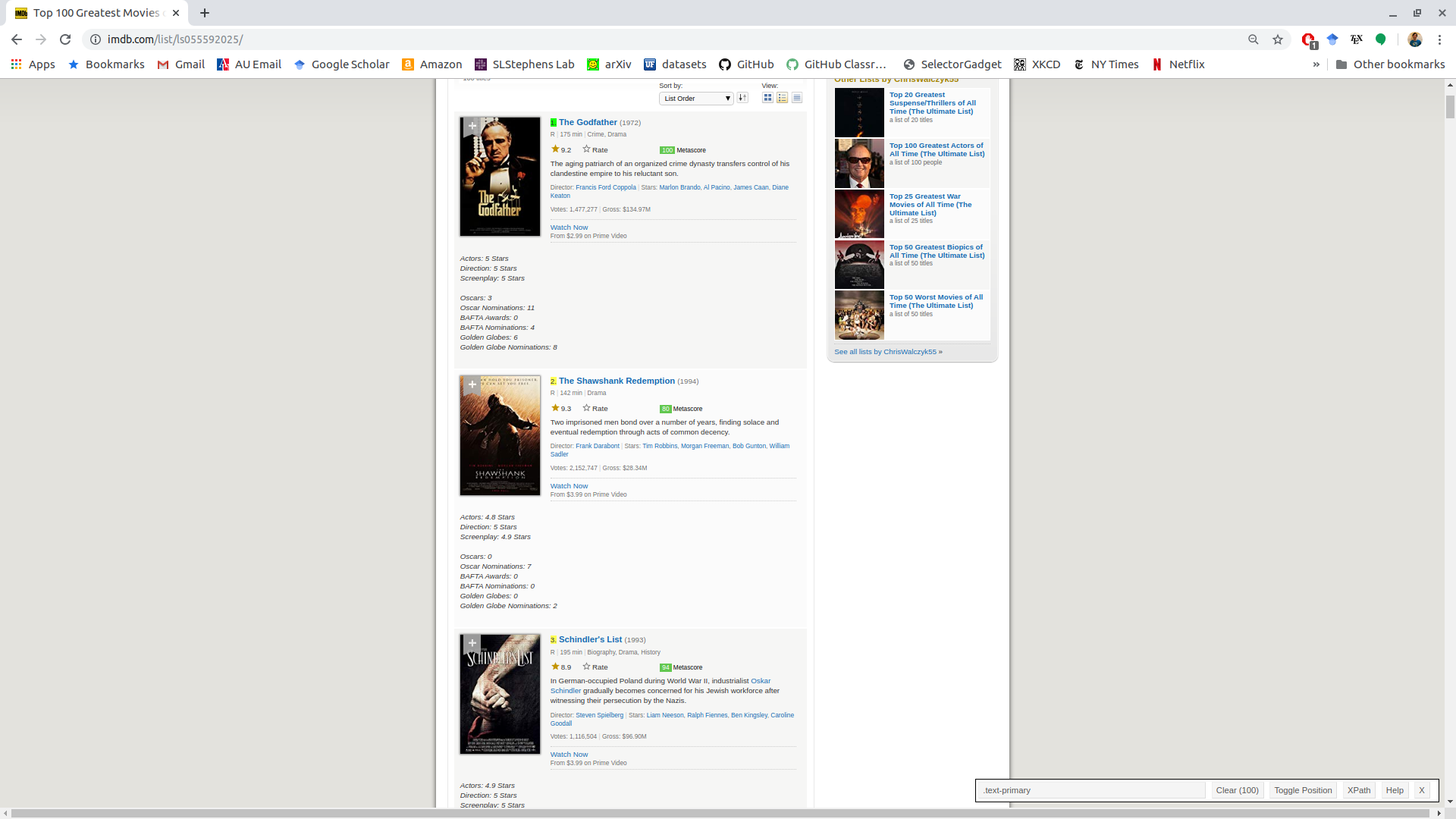
The “.text-primary” is the selector associated with the “1” we clicked on.
Everything highlighted in yellow also has the “.text-primary” selector associated with it.
We will also want the name of the movie. So if we click on that we get the selector associated with both the rank and the movie name: “a , .text-primary”.
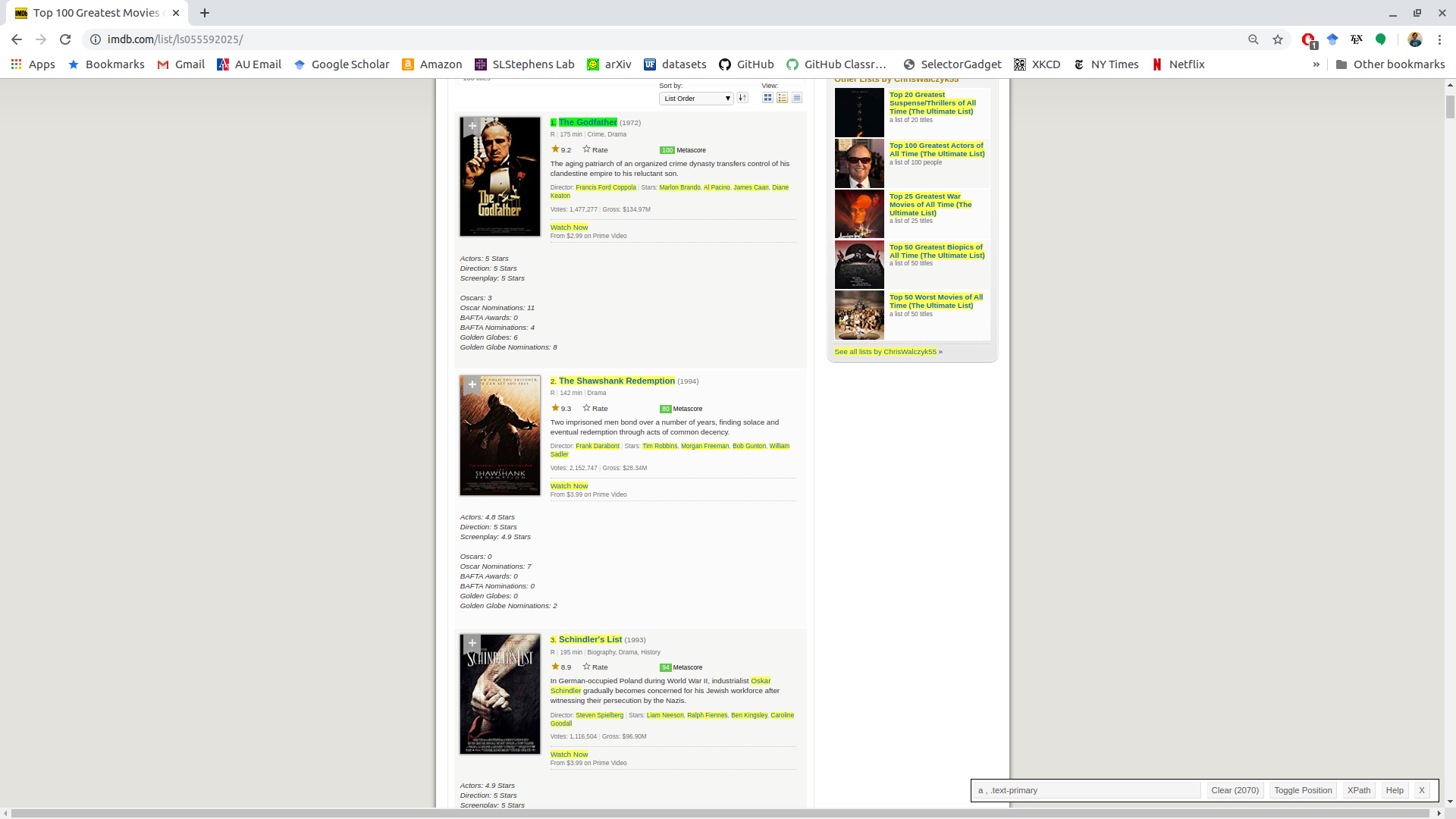
But we also got a lot of stuff we don’t want (in yellow). If we click one of the yellow items that we don’t want, it turns red. This indicates that we don’t want to select it.
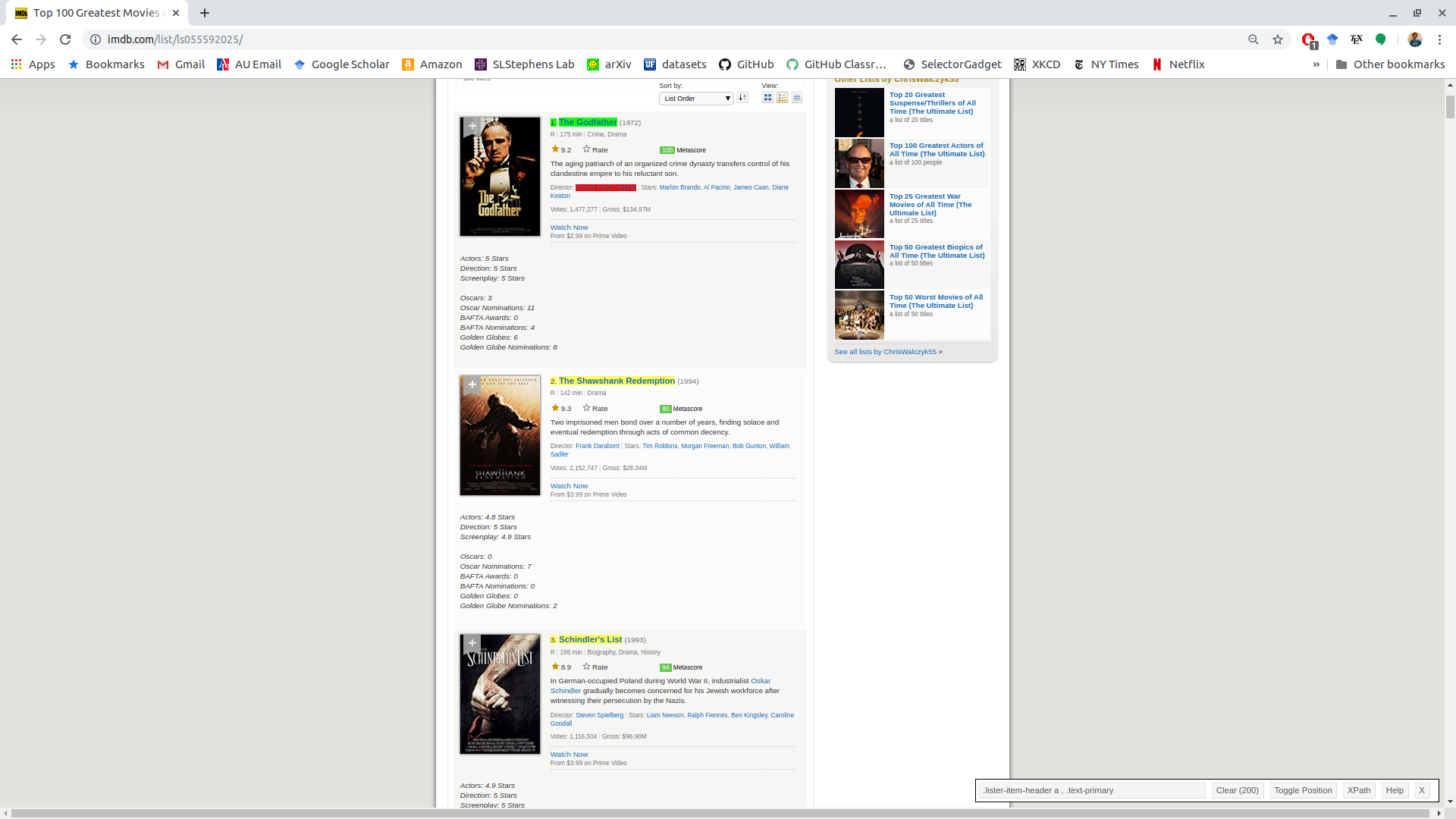
Only the ranking and the name remain, which are under the selector “.ipc-title-link-wrapper .ipc-title__text–reduced”.
It’s important to visually inspect the selected elements throughout the whole HTML file. SelectorGadget doesn’t always get all of what you want, or it sometimes gets too much.
What selector can we use to get just the names of each film, the metacritic score, and the IMDB rating?
Here is what I got:
".ipc-rating-star--rating , .metacritic-score-label, .ipc-title-link-wrapper .ipc-title__text--reduced"Chrome developer tools:
If you have trouble with SelectorGadget, you can also use the Chrome developer tools.
Chrome works best for web scraping (better than Safari/Edge/Firefox/etc). So install it if you don’t have it.
Open up the list of all selectors with: ⋮ > More tools > Developer tools.
Clicking on the element selector on the top left of the developer tools will show you what selectors are possible with each element.
You can also right click on the part of the website you are interested in and then click “Inspect”.
In the developer tools, hover over the element you are interested, right click, and then click Copy > Copy selector. This gives you the selector for that element that you can then inspect.
More rvest
Let’s do a more complicated example of
rvest.Use
read_html()to save an HTML file to a variable. The variable will be an “xml_document” objecthtml_obj <- read_html("https://www.imdb.com/list/ls055592025/") html_obj class(html_obj)Try
read_html_live()if you noticeread_html()is not working.XML stands for “Extensible Markup Language”. It’s a markup language (like HTML and Markdown), useful for representing a document.
rvestwill store the HTML file as an XML.We can use
html_elements()and the selectors we found in the previous section to get the elements we want. Insert the found selectors as thecssargument.ranking_elements <- html_elements(html_obj, css = ".ipc-title-link-wrapper .ipc-title__text--reduced") head(ranking_elements){xml_nodeset (6)} [1] <h3 class="ipc-title__text ipc-title__text--reduced">1. The Godfather</h3> [2] <h3 class="ipc-title__text ipc-title__text--reduced">2. The Shawshank Red ... [3] <h3 class="ipc-title__text ipc-title__text--reduced">3. Schindler's List< ... [4] <h3 class="ipc-title__text ipc-title__text--reduced">4. Raging Bull</h3> [5] <h3 class="ipc-title__text ipc-title__text--reduced">5. Casablanca</h3> [6] <h3 class="ipc-title__text ipc-title__text--reduced">6. Citizen Kane</h3>Note:
html_element()is similar, but will return exactly one response per element, so is useful if some elements have missing components.To extract the text inside the obtained nodes, use
html_text()orhtml_text2():html_text2()just does a little more pre-formatting (like converting line breaks from HTML to R code, removing white spaces, etc). So you should typically use this.
ranking_text <- html_text2(ranking_elements) head(ranking_text)[1] "1. The Godfather" "2. The Shawshank Redemption" [3] "3. Schindler's List" "4. Raging Bull" [5] "5. Casablanca" "6. Citizen Kane"After you do this, you need to tidy the data using your data munging tools.
tibble(text = ranking_text) |> separate(col = "text", into = c("ranking", "movie"), sep = "\\.", extra = "merge") -> movierank movierank# A tibble: 100 × 2 ranking movie <chr> <chr> 1 1 " The Godfather" 2 2 " The Shawshank Redemption" 3 3 " Schindler's List" 4 4 " Raging Bull" 5 5 " Casablanca" 6 6 " Citizen Kane" 7 7 " Gone with the Wind" 8 8 " The Wizard of Oz" 9 9 " One Flew Over the Cuckoo's Nest" 10 10 " Lawrence of Arabia" # ℹ 90 more rows
Extract the directors and the names of each film. Try to use SelectorGadget to find your own selectors.
There are probably multiple ways to do this. But I used ".dli-parent" to get get the movies. Then I did two separate calls to html_element() with ".ipc-title__text--reduced" to get the titles and ".bDNbpf span" to get the directors.
html_elements(html_obj, ".dli-parent") |>
html_element(".ipc-title__text--reduced") |>
html_text2() ->
titvec
html_elements(html_obj, ".dli-parent") |>
html_element(".bDNbpf span") |>
html_text2() ->
dirvec
tibble(title = titvec, dir = dirvec) |>
separate(col = "title", into = c("rank", "title"), sep = "\\.") |>
mutate(dir = str_extract(string = dir, pattern = "Director.+Stars")) |>
mutate(dir = str_remove(dir, "^Directors*")) |>
mutate(dir = str_remove(dir, "Stars*$"))# A tibble: 100 × 3
rank title dir
<chr> <chr> <chr>
1 1 " The Godfather" Francis Ford Coppola
2 2 " The Shawshank Redemption" Frank Darabont
3 3 " Schindler's List" Steven Spielberg
4 4 " Raging Bull" Martin Scorsese
5 5 " Casablanca" Michael Curtiz
6 6 " Citizen Kane" Orson Welles
7 7 " Gone with the Wind" Victor Fleming
8 8 " The Wizard of Oz" Victor FlemingGeorge CukorNorman Ta…
9 9 " One Flew Over the Cuckoo's Nest" Milos Forman
10 10 " Lawrence of Arabia" David Lean
# ℹ 90 more rowsA very simple example
Here is a very simple html file that is generated using
rvest:html <- minimal_html(" <h1>This is a heading</h1> <p id='first'>This is a paragraph</p> <p class='important'>This is an important paragraph</p> ")The
h1selector selects forh1tags.html_elements(html, "h1") |> html_text()[1] "This is a heading"The
.importantselector selects forclassattribute that isimportanthtml_elements(html, ".important") |> html_text()[1] "This is an important paragraph"The
#firstselector selects foridattribute that isfirsthtml_elements(html, "#first") |> html_text()[1] "This is a paragraph"
Bigger example using rvest
You typically use
html_elements()andhtml_element()together. You first usehtml_elements()to select observations. You then usehtml_element()to select values of variables from each observation.Let’s try and get the name, rank, year, and metascore for each movie.
I played with the developer tools until I saw that
- “.ipc-metadata-list-summary-item” extracts each movie
- “.ipc-title” extracts the title from a movie
- “.metacritic-score-box” extracts the meteascore from a movie
- “.dli-title-metadata-item” extracts the year, runtime, and rating for each movie
movie_list <- html_elements(html_obj, ".ipc-metadata-list-summary-item")
length(movie_list) ## should be 100[1] 100tibble(
title = movie_list |>
html_element(".ipc-title") |>
html_text2(),
meta = movie_list |>
html_element(".metacritic-score-box") |>
html_text2(),
year = movie_list |>
html_element(".dli-title-metadata-item") |>
html_text2()
)# A tibble: 100 × 3
title meta year
<chr> <chr> <chr>
1 1. The Godfather 100 1972
2 2. The Shawshank Redemption 82 1994
3 3. Schindler's List 95 1993
4 4. Raging Bull 90 1980
5 5. Casablanca 100 1942
6 6. Citizen Kane 100 1941
7 7. Gone with the Wind 97 1939
8 8. The Wizard of Oz 92 1939
9 9. One Flew Over the Cuckoo's Nest 84 1975
10 10. Lawrence of Arabia 100 1962
# ℹ 90 more rowsWe could of course clean the title column here into rank and title.
If we wanted the runtime and rating, we could loop over the movie list that we created and extract out each of the three elements that belong to “.dli-title-metadata-item”
year_vec <- rep(NA, length = length(movie_list))
runtime_vec <- rep(NA, length = length(movie_list))
rating_vec <- rep(NA, length = length(movie_list))
for (i in seq_along(movie_list)) {
movie_list[i] |>
html_elements(".dli-title-metadata-item") |>
html_text2() ->
x
year_vec[[i]] <- x[[1]]
runtime_vec[[i]] <- x[[2]]
rating_vec[[i]] <- x[[3]]
}
head(year_vec)[1] "1972" "1994" "1993" "1980" "1942" "1941"head(runtime_vec)[1] "2h 55m" "2h 22m" "3h 15m" "2h 9m" "1h 42m" "1h 59m"head(rating_vec)[1] "R" "R" "R" "R" "PG" "PG"html_table()
When data is in the form of a table, you can format it more easily with
html_table().The Wikipedia article on hurricanes in 2024: https://en.wikipedia.org/wiki/2024_Atlantic_hurricane_season
If the above link fails, try: https://data-science-master.github.io/lectures/08_web_scraping/wiki_2.html
This contains many tables which might be a pain to copy and paste into Excel (and we would be prone to error if we did so). Let’s try to automate this procedure.
Save the HTML
wikixml <- read_html("https://en.wikipedia.org/wiki/2024_Atlantic_hurricane_season")We’ll extract all of the “table” elements.
wikidat <- html_elements(wikixml, "table")Use
html_table()to get a list of tables from table elements:tablist <- html_table(wikidat) class(tablist)[1] "list"length(tablist)[1] 27tablist[[3]]# A tibble: 10 × 3 Rank Cost Season <int> <chr> <int> 1 1 ≥ $294.803 billion 2017 2 2 $172.297 billion 2005 3 3 $130.438 billion 2024 4 4 $117.708 billion 2022 5 5 ≥ $80.827 billion 2021 6 6 $72.341 billion 2012 7 7 $61.148 billion 2004 8 8 $54.336 billion 2020 9 9 ≥ $50.526 billion 2018 10 10 ≥ $48.855 billion 2008You can clean up, bind, or merge these tables after you have read them in.
The Wikipedia page on the oldest mosques in the world has many tables: https://en.wikipedia.org/wiki/List_of_the_oldest_mosques
If the above link fails, try: https://data-science-master.github.io/lectures/08_web_scraping/mosque_2.html
- Use
rvestto read these tables into R. - Merge the data frames together. You only need to keep the building name, the country, and the time it was first build.
It’s easier if you use a css selector of "table.wikitable" with html_elements() first to get the table rather than just "table". I found this out by getting to the developer tools in Chrome with CTRL + Shift + I then playing around with the tables.
mosque <- read_html("https://data-science-master.github.io/lectures/05_web_scraping/mosque.html")mosque |>
html_elements("h3") |>
html_text2() ->
catvec
catvec <- c("Mentioned in Quran", catvec)
mosque |>
html_elements("table.wikitable") |>
html_table() ->
tablist
## Errors if you try bind_rows() because some are integers and some are characters
for (i in seq_along(tablist)) {
if (any(names(tablist[[i]]) == "First built")) {
names(tablist[[i]])[names(tablist[[i]]) == "First built"] <- "date"
tablist[[i]]$date <- str_remove_all(tablist[[i]]$date, "\\[.*\\]")
}
}
tb <- bind_rows(tablist)
tb |>
select(Building, Location, Country, date, Notes, Tradition)# A tibble: 176 × 6
Building Location Country date Notes Tradition
<chr> <chr> <chr> <chr> <chr> <chr>
1 Al-Haram Mosque Mecca Saudi … Unkn… "Al-… <NA>
2 Haram al-Sharif, also known as the Al… Jerusal… Palest… Cons… "Al-… <NA>
3 The Sacred Monument Muzdali… Saudi … Unkn… "Al-… <NA>
4 Quba Mosque Medina Saudi … 622 "The… <NA>
5 Mosque of the Companions Massawa Eritrea 620s… "Bel… ""
6 Al Nejashi Mosque Negash Ethiop… 7th … "By … ""
7 Mosque of Amr ibn al-As Cairo Egypt 641 "Nam… ""
8 Mosque of Ibn Tulun Cairo Egypt 879 "" ""
9 Al-Azhar Mosque Cairo Egypt 972 "" "Sunni"
10 Arba'a Rukun Mosque Mogadis… Somalia 1268… "" "Sunni"
# ℹ 166 more rows